AZtecFeature Tips and Tricks – Classification
As I mentioned in my last blog on AZtecFeature, automated feature analysis is a powerful tool for understanding samples consisting of particles/inclusions/grains/features. It can be used to understand the details of large populations – giving information on the relative abundance of different constituents or to find rare features amongst many others – perhaps contaminants that shouldn’t be there or a key piece of evidence.
Of course, we only do Feature analysis because we want to find something out – to answer a question. This means that some interpretation must be involved and how we can at least start the interpretation process as part of our analysis.
So, what sort of questions might we be trying to answer? Consider:
- Does my additive manufacturing powder have any contaminants in it and if so, what are they? (So that I can work out how to prevent them being there).
- What is the inclusion content of my steel – what size and type are those inclusions?
- Does the sample that I collected from a shooting suspect contain gunshot reside particles and if so, how many?
- Is the car component that I have received from a supplier sufficiently clean? What particles are on it and what size are they?
All of these questions can be answered by, or at least be answered with information from, a classification scheme.
So, what is a classification scheme? Fundamentally, it is a way of putting the features that we analyse into a series of different groups (known as classes), defined by rules. Each class can contain multiple rules relating to the feature’s composition and/or morphology. These rules are known as criteria and can be of several types – the most common of which is a rule relating to a single parameter. To demonstrate this, let’s imagine that we want to classify particles that are made of aluminium oxide, Al2O3, into a group together. Aluminium oxide contains 52.93wt% Al and 47.08wt% O. Therefore, in order to create a class that captures these features, we could set up two criteria – one that requires Al to be present between 43wt% and 63wt% and another that requires O to be present between 37wt% and 57wt%. Any features that meet both criteria would go into the aluminium oxide class.
In the image below you can see an example of this…

I normally allow a reasonably large range of compositions in my criteria to allow for small concentrations impurities that are not really of any significance and the natural variability of samples. This might lead to the suspicion that we could end up putting too many features into that class but the combination of multiple criteria counters that risk – I am classifying more on the combination of elements than the specific compositional values. However, it is of course completely up to you how you set your limits!
There may sometimes be occasions where Al and O are both present within the concentration ranges we have specified, but are joined by a third element, e.g. Si which would mean that we would no longer want to put this feature into our aluminium oxide class. In order to deal with this, we could add a third criterion, an exclusion rule, which specifies that if Si is present above a certain level, then the feature should not fall into this class. We have now extended our classification scheme to give what you see below.

You can build classification schemes in a number of ways – in this case I manually chose which elements I wanted to make rules from and added them myself. I knew in advance that my sample contained aluminium oxide and I wanted to make sure I found it. An alternative, and often more powerful, approach is to build the classification from the data that has been acquired.
In the image below, I have selected a number of grains (the selected ones are those which have thick, white outlines in the image) which, by looking at the data table and details of those individual grains, I have identified to be of the same class. After I made that selection, I created a new class. When that class was created, the criteria were automatically defined based upon the particles that were chosen. Only the elements that were common to all particles – in this case Pb and S, had criteria created with the range being defined by the maximum and minimum concentration values for those 2 elements across the whole dataset. As soon as the class was created, the rest of the features were checked to see if any of those fell into the same class – and you can see that many did – shown in red but without the heavy outline. This means that we can very quickly see that our scheme is doing the job we need it to in grouping together similar particles.
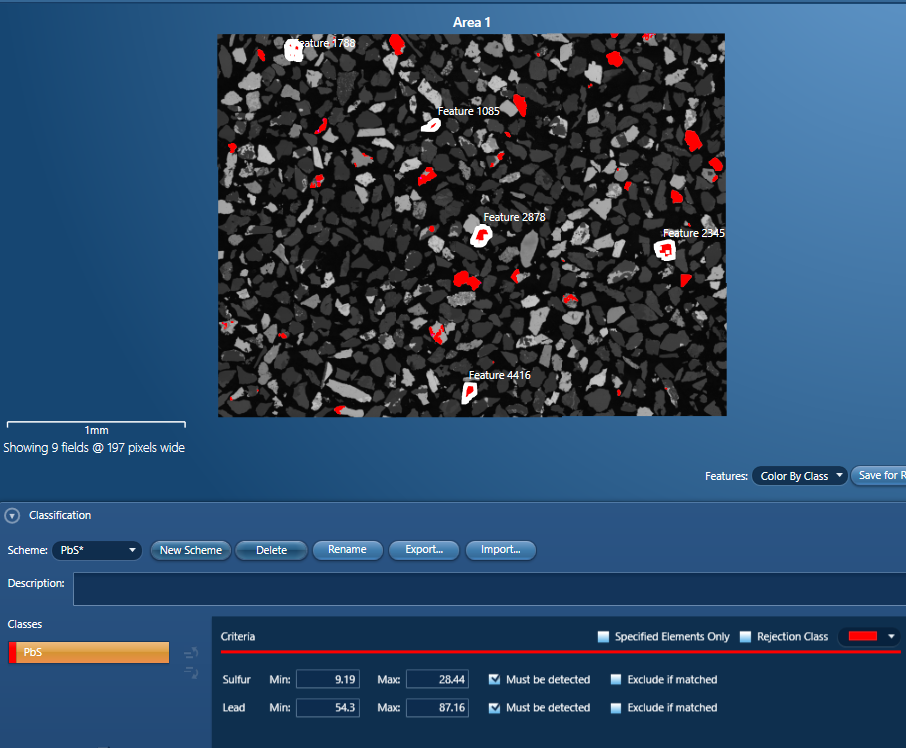
We call this approach of creating classes based on the features that have been acquired assisted classification – and it is a really powerful and quick way of building up a scheme. It has the big advantage that your classification scheme is tailor made for your sample and you are getting instant feedback on how many other particles fall into the same class as you make your scheme.
The things that we’ve discussed here today only scratch the surface of what you can achieve with classifications. To find out more about the potential of AZtecFeature for streamlining your sample analysis, book a demo now.
Book a Demo






